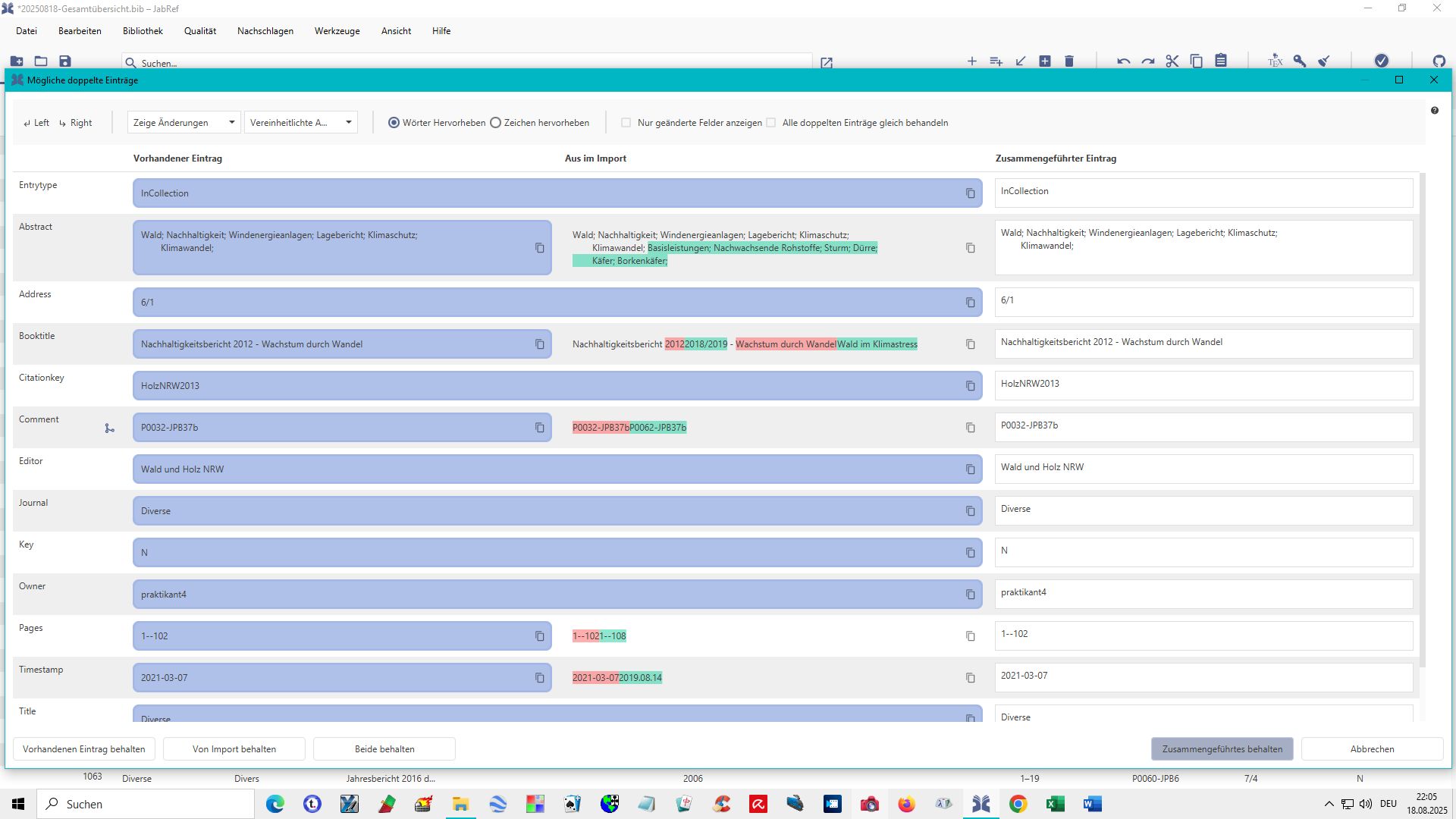
Trotz Neuinstallation von JabRef (Windows 10) habe ich nach wie vor folgendes Problem seit ca. Mitte Juli 2025: Beim Einfügen von Datensätzen einer bib-Dateitabelle (kopiert) in eine andere bib-Dateitabelle (<einfügen>) prüft JabRef offenkundig Datensatz für Datensatz der vorhandenen und einzufügenden Datensätze auf Dopplungen aller vorhandenen Felder. Zuerst wurde bei jedem Treffer eine Übersicht angezeigt (siehe unten), worin die Dopplungen bestanden, ich habe natürlich dort auf “Beide Dateien behalten” geklickt. Dann kam die nächste Meldung - uns so ging das selbst bei relativ wenigen Datensätzen sehr lange. Ich habe aber Tausende Datensätze in eine bib-Dateitabelle zu kopieren bzw. einzufügen! Die o. a. Meldung bot dann auch noch an die Möglichkeit “Für alle Dateien die gleiche Entscheidung anwenden” - bei mir also beide Dateien behalten. Seitdem kommt o. a. Übersicht nicht mehr, aber bei dem Versuch, ca. 1000 Datensätze in eine Tabelle mit gut 3000 Datensätze einzufügen, war JabRef fast eine Stunde nicht ansprechbar (Sanduhr) - dann waren die meisten Datensätze eingefügt, aber einige fehlten trotz der Vorgabe, beide Datensätze bei Dopplungen zu behalten. Ich muss aber noch gut 10.000 Datensätze in die erwähnte Empfängertabelle einfügen - bloß wie?? Diese Erscheinung habe ich nicht nur zu Hause (Home Office), sondern auch in meinem Verein, für den ich die Datenerfassung der Fachliteratur durchführe. Ich habe im August 2025 schon mal hierzu angefragt, leider aber keinen Lösungsvorschlag erhalten.Vielleicht kann mir ja doch noch jemand helfen - vielen Dank schon mal.
Hallo, danke für die Problemmeldung. Wir schaun uns das in den nächsten Tagen mal an. Tut uns leid, dass das im August wohl durchgerutscht ist. Wir hatten vor ein paar Wochen in discourse eine Spam-Attacke, kann sein, dass das weggekommen ist.
Leider sind wir nicht viele Entwickler und machen das nur als hobby neben dem Beruf, daher kann ich nicht versprechen, wie schnell wir uns das anschauen können.
Wenn ich das problem richtig verstanden habe geht es um zweierlei: Erstens die Verarbeitungsgeschwindigkeit und zweitens, dass tatsächlich nicht die Doppelungen behalten werden?
Derzeit bleibt nur der Workaround, einen Texteditor zu benutzen. Man kann die eine .bib-Datei öffen, die betreffenden Einträge kopieren und in die andere .bib-Datei einfügen. Dafür bitte JabRef geschlossen haben und erst danach die andere .bib-Datei öffnen.
Zur Nachverfolgung: Die Anfrage vom August ist diese hier Tabellen kopieren
Es wurde bisher JabRef 5.15 benutzt. Wir fokussieren uns derzeit auf die 6.x-Release, da wir als Team uns entschieden haben nur einen main-Branch zu pflegen, da wir lieber sowohl Verbesserungen als auch neue Features haben wollen als weniger neue Features (bei der Pflege von zwei oder mehr “stabilen” alten Versionszweigen).
Es wäre also wirklich nett, wenn der neueste Developer-Build verwendet werden würde. Wir versuchen wirklich, diesen nutzbar zu halten und nutzen diesen auch in unserer täglichen Arbeit.
Herzlichen Dank allen, die sich meines Problems angenommen haben, besonders aber koppor, der mir mit seinem Quelltexthinweis eine zuverlässige Lösung gezeigt hat. Was meine JabRef-Version betrifft: Ich habe im Juli 2025 die aktuellste herunter geladen, eine 6…., nach der Installation war es aber die Version 5.15.
Ich ärgere mich ein wenig, dass ich nicht selbst auf diese Lösung gekommen bin, denn die Struktur von BibTex-Quelltext hat doch ziemliche Ähnlichkeiten mit der vom Quelltext von html-Dateien. Ich habe mal eine Bildergalerie mit html-Dateien gemacht, in denen die Bilder zunächst als tumbnails und Texte gezeigt wurden und beim Anklicken dann das Großbild - manche der Dateien umfassen bis zu 200 Bilder. Die Strukturen von BibTex-Quelltexten und obigen html-Quelltexten unterscheiden sich eigentlich nur dadurch, dass die Einträge bzw. Datensätze bei ersteren in @ und } und bei html in meinem Fall als tables in und eingeschlossen sind - hätte mir doch auffallen müssen! Danke noch mal und tschüss - der Reeser